How RAG makes technical documentation actually useful
RAG (retrieval-augmented generation) is a method that retrieves the most relevant chunks of your documentation and feeds them to a language model, which then writes a direct answer grounded in that text. It is the difference between a user typing "how do I configure webhooks" and getting fifteen ranked links, versus getting one answer with citations back to the exact pages it came from.
We run RAG across hundreds of documentation sites, and the pattern is consistent: the moment readers can ask a question in plain language and get a grounded answer, search-result fatigue drops and so do support tickets. This post is what we have learned about how RAG works for docs, why it beats the alternatives, and where it quietly fails.
What RAG does for documentation
RAG turns your docs from a static reference you search into a source a model answers from. It joins two steps into one pipeline: retrieval finds the passages that matter, and generation turns them into prose.
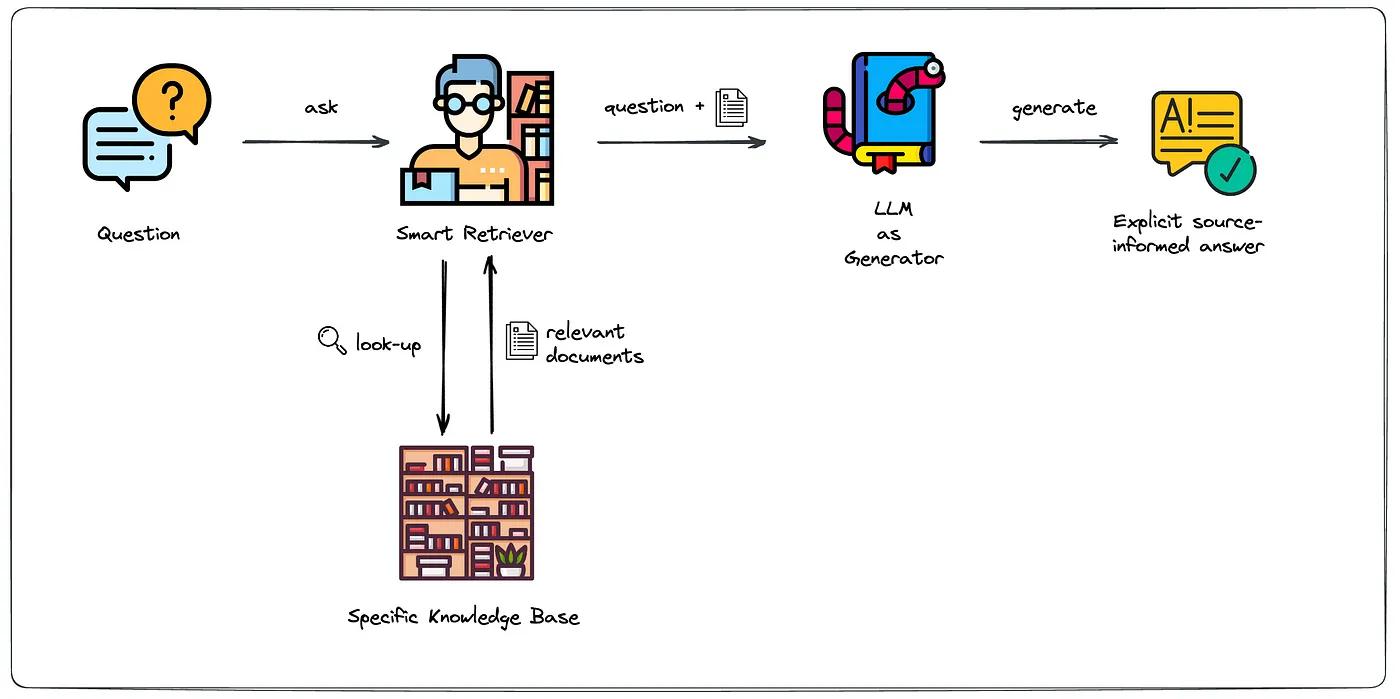
Image from Leveraging LLMs on your domain-specific knowledge base
In the retrieval step, the system converts the user's question into a vector embedding and searches a pre-indexed copy of your documentation, returning the closest passages (typically three to ten). In the generation step, a model such as GPT-4o or Claude receives those passages as context and composes an answer from them.
The output a reader sees is a specific answer with source links, not a generic response assembled from whatever the model absorbed during training. That grounding is the whole point: the answer is only as good, and only as current, as the docs behind it.
Why a raw LLM is not enough on its own
A standalone LLM cannot reliably answer questions about your product because it was never trained on your product. It writes fluent text, but for documentation it carries three liabilities that RAG exists to remove.
- Stale knowledge. The model knows only what was in its training data. The API parameter you shipped last week is invisible to it.
- Hallucination. With no source text to anchor it, a model will confidently invent an endpoint, a flag, or a default that does not exist. In docs, a confident wrong answer is worse than no answer.
- No citations. A reader has no way to verify a bare LLM response, and verification is exactly what technical readers want.
RAG addresses all three at once. Retrieval forces the model to work from your current docs, generation makes the result readable, and because you know which chunks were retrieved you can show the source links beside the answer. The model is no longer the knowledge base; your docs are, and the model is the writer.
How a docs RAG pipeline works in practice
A documentation RAG pipeline is five stages: crawl, chunk, embed, index, and query. Each stage has a decision that shows up later in answer quality.
- Crawl. Your pages are fetched through a sitemap, a set of URLs, a connected repository, or file uploads. Whatever is not crawled cannot be answered, so coverage decisions start here.
- Chunk. Pages are split into passages, commonly 500 to 1000 tokens with a small overlap so a sentence is not cut off from the heading that gives it meaning.
- Embed. Each chunk becomes a vector through an embedding model such as
text-embedding-3-small. These vectors capture meaning, so "auth token" and "API key" can match even when the words differ. - Index. Vectors are stored in a vector database (Qdrant, Pinecone, Typesense, and similar) alongside the original text and metadata like page title, URL, and section heading.
- Query. A reader's question is embedded with the same model, the nearest chunks are retrieved, and those chunks plus the question go to the LLM, which answers from them.
The two stages teams under-invest in are chunking and metadata. Both are cheap to get wrong and expensive to debug, because the model dutifully answers from whatever you handed it, even when what you handed it was the wrong slice of a page.
Build it yourself or use a hosted service
The honest tradeoff is control versus time: building your own RAG stack gives you full control over every component, and a hosted service gives you a working chatbot in an afternoon. Most documentation teams do not have a custom-retrieval requirement that justifies owning the pipeline.
| Build your own | Hosted service | |
|---|---|---|
| Setup | Weeks of engineering (LangChain, LlamaIndex) | Point it at your docs, live in minutes |
| Control | Tune chunking, retrieval, prompts | Sensible defaults, fewer knobs |
| Maintenance | You own re-crawling and scaling | Automatic re-indexing on docs changes |
| Cost | Embeddings, vector DB, LLM billing | One monthly fee |
We build Biel.ai as the hosted option: you connect a sitemap, a Git repository, or uploaded files, and it handles crawling, chunking, embedding, indexing, and re-indexing when your docs change. You can see the full list of inputs on the documentation sources page in our docs. Build your own when you need data residency guarantees or genuinely custom retrieval logic; otherwise the maintenance bill rarely pays for itself.
What to monitor after launch
RAG is not set-and-forget, because answer quality drifts as your docs and your users change. Four signals tell you whether it is still working.
- Answer relevance. Are retrieved chunks actually about the question? Thumbs up/down feedback on each answer is the cheapest read on this.
- Unanswered questions. The share of queries that surface no relevant passage is a direct map of your documentation gaps. Treat it as a backlog, not a failure.
- Source coverage. Confirm every section is indexed. Pages behind authentication, JavaScript-rendered content, and PDFs are the usual silent omissions.
- Freshness. Stale indexes produce stale answers. Re-crawl after every docs deploy so the index never lags the site.
Teams that pair this monitoring with active docs improvement tend to climb past 60% answer coverage within a few months, because every unanswered question becomes a page they write. We cover the full method in how to tell if your documentation chatbot is actually working.
Common pitfalls we see
The failures are rarely in the model; they are in how the docs were prepared for it. These are the four we see most often across the sites we run.
- Chunks that are too small lose context. A code snippet with none of the surrounding explanation gives the model nothing to reason from, so it pads the gap or declines to answer.
- Chunks that are too large dilute relevance. A 5000-token chunk spanning three topics matches loosely and answers poorly, because the signal for any one question is buried.
- Stripped metadata. Page titles, section headings, and URLs help retrieval rank and help readers verify. Drop them and you lose both precision and the citation.
- No feedback loop. Without ratings on answers, you cannot measure quality or catch a regression after a re-crawl. You are flying blind on the one metric that matters.
There is a fifth, more fundamental limit worth naming: RAG cannot answer what your docs do not contain. If a topic is missing, retrieval returns the nearest-but-wrong passage and the model writes a plausible answer about the wrong thing. RAG surfaces your documentation gaps; it does not fill them. That is also why writing docs with retrieval in mind pays off, which we get into in optimizing docs for AI agents.
Frequently asked questions
Is RAG the same as fine-tuning a model on my docs?
No. Fine-tuning bakes knowledge into the model's weights and goes stale the moment your docs change; you would retrain to update it. RAG keeps your docs in an external index the model reads at query time, so a re-crawl updates the answers without touching the model. For documentation that ships frequently, RAG is almost always the right call.
How current are RAG answers?
As current as the last crawl of your index. If you re-crawl after every docs deploy, answers reflect your live documentation; if you index once and forget, answers drift as your product moves. This is why freshness is a metric to monitor, not a one-time setup step.
Why does my RAG chatbot still give wrong answers?
Usually because the answer is not in the indexed docs, the chunking split the relevant context apart, or a section was never crawled (auth-gated pages, JavaScript content, and PDFs are common culprits). Wrong answers are most often a coverage or chunking problem, not a model problem. Reviewing unanswered and low-rated questions points you straight at the cause, and improving the reader-facing experience helps too, as we describe in how to improve the user experience of an AI chatbot on your docs site.
Do I need a vector database to use RAG?
For anything beyond a toy, yes. Retrieval depends on comparing embeddings at speed, and a vector database (Qdrant, Pinecone, Typesense, and others) is built for that. A hosted service includes one, so you never provision or scale it yourself.
Try RAG on your own docs
RAG turns your documentation into something a reader can talk to: questions in, grounded answers out, with links to verify every claim. The method is straightforward; the work is in coverage, chunking, and the feedback loop that keeps quality from drifting.
If you would rather skip building the pipeline, Biel.ai handles the full RAG stack for documentation sites, and setup takes about fifteen minutes. Try it free for 14 days.