How to tell if your documentation chatbot is actually working
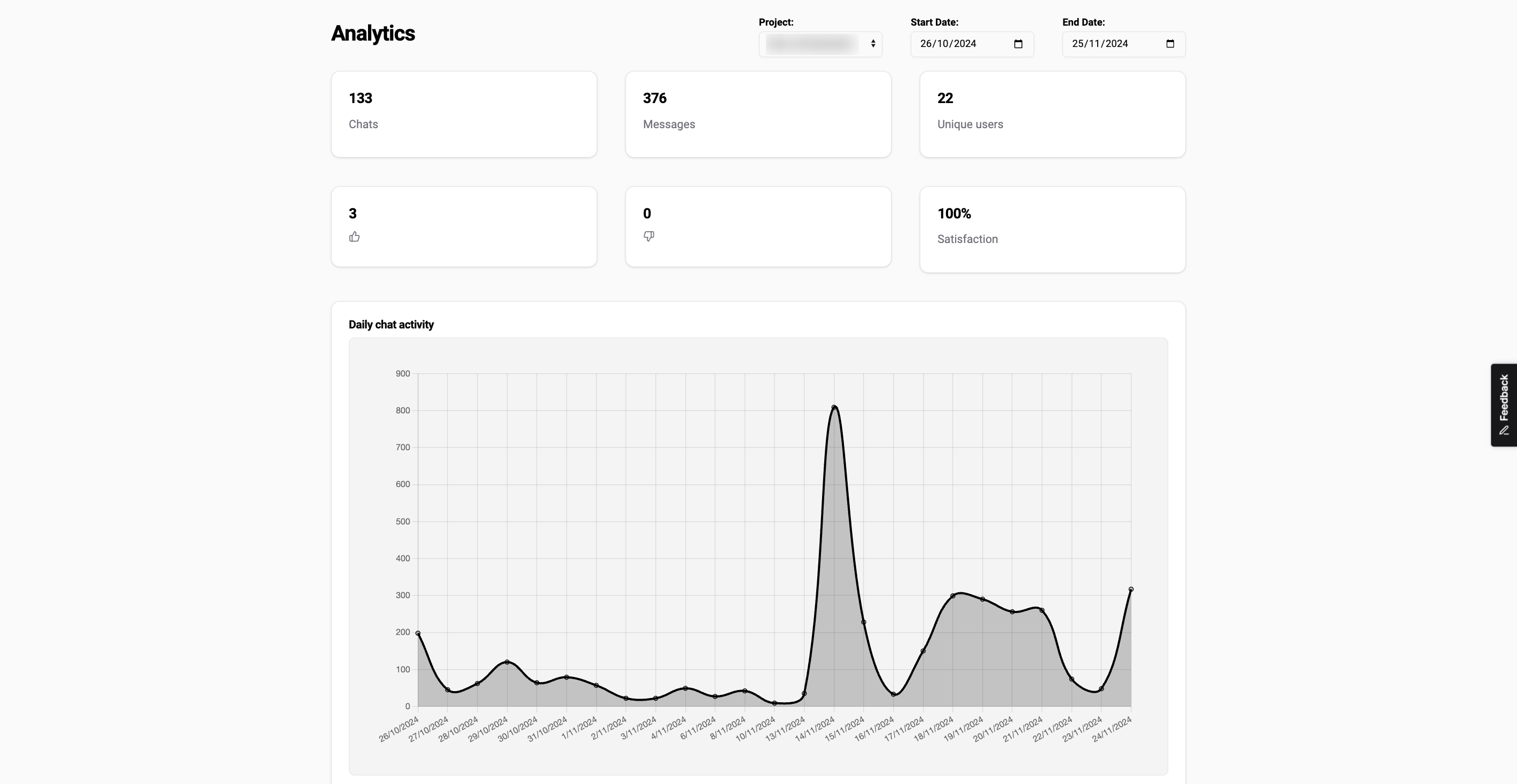
A docs chatbot can feel like it works and still fail most of its users. It answers fluently, collects a few thumbs-up, and the support team says it "seems to help." None of that is evidence. We see the same pattern across hundreds of documentation sites: the widget gets clicks, morale is high, and nobody can say whether questions are actually getting resolved.
This post defines the four metrics that turn that gut feeling into a score you can defend, the benchmarks to measure against, and the failure modes the numbers expose before a user ever complains.
"Feels good" is not a metric
"Feels good" is the most common way a chatbot deployment fools its own team, because fluency and correctness are independent. A retrieval-augmented chatbot (RAG: it retrieves relevant doc chunks, then generates an answer grounded in them) produces confident prose whether or not it found the right source. The confidence is a property of the language model, not of the answer.
That decoupling creates three blind spots. The chatbot can be wrong while sounding right. It can cover the easy, high-volume questions while silently failing every edge case. And it can answer well while almost nobody uses it. A thumbs-up count catches none of these, because it only measures the subset of users who both got an answer and bothered to rate it.
The fix is not more vibes. It is four metrics, each with a clean definition and a benchmark, reviewed on a fixed cadence.
Answer relevance: does the reply address the question
Answer relevance is the share of responses that are genuinely about what the user asked, regardless of whether the answer is complete or correct. It is the baseline metric: an irrelevant answer fails before accuracy is even worth checking.
The cheapest proxy is the thumbs-up/thumbs-down ratio on responses. Aim for 70% positive in the first weeks after launch and 80%+ after a month of iteration. Sitting below 60% almost always points at the retrieval layer rather than the model: chunks are too small to carry context, key pages were never indexed, or the embeddings are not matching user phrasing to your content.
Relevance is the metric most flattered by self-selection. Users who get a bad answer often leave without rating it, so a 75% thumbs-up rate on a low response volume tells you less than the number suggests. Read it alongside coverage, never alone.
Faithfulness: does the answer stay grounded in your docs
Faithfulness is whether the chatbot's answer is supported by your actual documentation rather than plausible text the model invented to fill a gap. A fabricated API parameter, an invented version number, or a made-up pricing tier is a faithfulness failure even if the sentence reads perfectly.
This is the hardest of the four to automate, so measure it by hand at first. Each week, pull 10 to 15 real questions from your logs, run them, and check every claim in each answer against the source page it cites. Anything you cannot find in the docs is a flag. The rate of flagged answers is your faithfulness signal, and the offending questions usually point straight at thin or contradictory documentation.
The honest limit here: a weekly spot check of 15 questions is a sample, not a guarantee. It catches systematic fabrication, not the rare one-off. Treat it as a smoke detector, not a proof. Once you have a few hundred logged answers, you can promote the spot check into a standing eval set: freeze a list of representative questions with the correct grounded answer, and re-run it after every meaningful docs or model change so a faithfulness regression shows up as a moved number rather than a user complaint.
Coverage rate: how many questions get a real answer
Coverage rate is the percentage of questions the chatbot answers from your docs rather than returning some version of "I couldn't find relevant information." Its inverse, the unanswered rate, is the single most actionable number you have, because every unanswered question is a documented gap or an indexing failure you can fix.
Some unanswered rate is healthy: users ask things that genuinely are not in your docs, and a chatbot that refuses to guess is behaving correctly. The problem is a high or stubborn unanswered rate. Above 20% after the first month usually means real content gaps or pages the crawler never reached, not bad luck.
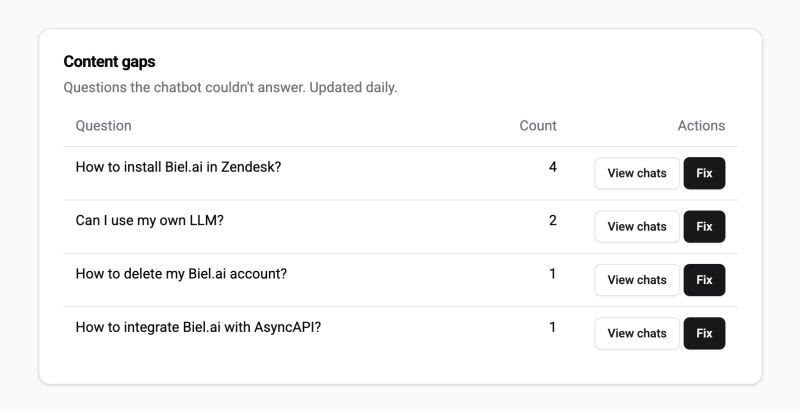
Coverage is where measurement turns into a writing backlog. Cluster the unanswered questions, and the clusters are your next docs pages, ranked by demand. A single phrasing of an edge case is noise; the same gap asked twenty different ways in a month is a page you should already have written. Sorting gaps by frequency is what keeps the writing effort pointed at the questions real users keep asking rather than the ones you assume they will.
Deflection rate: how many tickets the chatbot prevents
Deflection rate is the share of questions the chatbot resolves without the user escalating to human support. This is the metric your stakeholders care about, because it converts directly into cost and is the spine of any business case for AI search on a developer portal.
Measuring it cleanly means connecting chatbot analytics to support ticket volume over the same window. If docs-related tickets run 400 a month and drop to 270 after launch, you have deflected roughly 130 tickets. At a typical $15 to $25 per support ticket, that is $2,000 to $3,250 a month, and the conversation with finance stops being about feel.
The caveat is attribution. Ticket volume moves for reasons that have nothing to do with the chatbot: a buggy release spikes it, a quiet quarter drops it. Treat deflection as a trend across months with a stable denominator, not a single before-and-after snapshot, and you will not over- or under-claim.
The benchmarks: what good looks like
These are the ranges we see across typical documentation chatbot deployments. They are starting goalposts, not promises: your numbers shift with docs quality, audience, and question complexity.
| Window | Thumbs-up rate | Unanswered rate | Deflection rate |
|---|---|---|---|
| First week | 65–75% | 20–35% | Too early to read |
| First month | 75–85% | Below 15% | 25–40% |
| After three months | 80–90% | Below 10% | 35–50% |
The expected shape matters more than any single cell. A high unanswered rate in week one is normal and even useful, because it surfaces gaps you did not know you had. What should worry you is a number that refuses to improve after a month of fixing docs and re-indexing. A flat curve is a stronger signal than a low starting point.
The failure modes the numbers expose
The point of measuring is to read the failure mode behind a bad number, not just to log it. Four patterns account for most of what goes wrong.
- Unanswered rate high and not falling. After a month of adding docs, the bottleneck is usually indexing, not content. Check that every page is crawled. Auth-gated pages, JavaScript-rendered content, and some CMS setups get silently skipped.
- Thumbs-up rate declining over time. The index reflects your docs as of the last crawl. Ship a product change without re-indexing and users get stale answers. Automate re-indexing on every docs deploy.
- The same question, rephrased repeatedly. A user asks, gets a weak answer, rephrases, asks again. That session pattern means retrieval failed on a terminology mismatch: your docs and your users use different words for the same thing. A glossary or terminology-aware content closes the gap.
- Tickets flat despite good quality. If deflection will not move while relevance looks fine, the problem is adoption, not answers. A widget that is hard to find, slow, or dismissed as "just a bot" goes unused. Session counts tell you whether it is a quality problem or a placement problem.
Each of these is invisible to a thumbs-up count and obvious once you watch coverage, deflection, and session logs together. For the workflow of turning these signals into docs changes, see how technical writers use chatbot analytics to improve documentation quality.
The monthly review that keeps it honest
A 30-minute review once a month is enough to keep all four metrics moving in the right direction. The structure stays the same every time:
- Pull last month's numbers: thumbs-up rate, unanswered rate, deflection, total conversations.
- Open the unanswered and low-rated questions and note the top clusters.
- Spot-check 10 answers against the source docs for faithfulness.
- Turn the top clusters into a short, frequency-ranked list of docs to write or expand.
- Schedule a re-index once those updates ship, then confirm next month that the questions moved from unanswered to answered.
This loop, measure then fix then re-index then verify, is what separates a chatbot that compounds over time from one that plateaus in month two. Most of the leverage lives in retrieval quality, which is why how RAG makes technical documentation actually useful is worth reading alongside this.
In Biel.ai, the four metrics surface without manual setup: thumbs-up/thumbs-down is on by default, and the analytics dashboard groups unanswered and low-confidence questions into a Content Gaps view that maps straight onto step 4 above.
Frequently asked questions
What is a good thumbs-up rate for a docs chatbot?
Aim for 70% positive in the first weeks and 80% or higher after a month of iteration. Below 60% usually means a retrieval problem rather than a model problem: undersized chunks, unindexed pages, or embeddings that miss user phrasing. Read the rate alongside coverage, because users who get bad answers often leave without voting.
How do you measure deflection rate accurately?
Connect chatbot analytics to support ticket volume over the same window and watch the trend across several months, not a single before-and-after. A drop from 400 to 270 docs-related tickets is roughly 130 deflected, or $2,000 to $3,250 saved at $15 to $25 per ticket. Hold the denominator stable so a noisy release or a quiet quarter does not get mistaken for chatbot performance.
Why isn't a high thumbs-up rate enough on its own?
Because it only measures users who got an answer and chose to rate it, and because fluency is independent of correctness. A confident, well-written reply can be unfaithful to your docs, and the easy questions can score well while every edge case fails silently. Pair relevance with coverage rate and a weekly faithfulness spot check.
What does a high unanswered rate mean?
In week one it is normal and useful, because it exposes gaps you did not know about. After a month of writing docs and re-indexing, a stubborn rate above 20% points at indexing rather than content: check whether auth-gated, JavaScript-rendered, or CMS-hosted pages are actually being crawled.
Getting started
If you have not set up any measurement yet, start with two things: turn on thumbs-up/thumbs-down on every response, and watch your unanswered rate. Those two data points cover roughly 80% of what you need in the first month, and they tell you where the other metrics will break.
You can stand all four metrics up on Biel.ai's AI chat for docs and run the monthly loop from one dashboard. Try it free for 14 days and you will have a Content Gaps view within a few days of launch. The goal was never a chatbot that feels good to have. It is one you can prove is working, and prove is getting better.